I lead a team of undergraduate researchers in software engineering and NLP tool development at the Neural Tuning of Reading Lab, advised by Dr. Jeremy Purcell at the University of Maryland. My work centers on building computational linguistics pipelines for analyzing spelling-sound relationships, developing open source tooling for the research community, and running technical analyses for upcoming publications on reading and language processing.
Research Focus
The Neural Tuning of Reading lab investigates how neural mechanisms tune to spelling-sound relationships during reading acquisition. A core focus is the computational modeling of phonographeme mappings – the systematic correspondences between phonemes (speech sounds) and graphemes (letter sequences) – at multiple linguistic grain sizes (phoneme-grapheme, onset-rime, syllable level). English is an opaque orthography, meaning spelling-sound mappings are inconsistent, which makes it a particularly rich domain for building NLP tools that quantify and analyze these irregularities.
Key research areas include:
- Orthography-phonology coupling in the brain
- Developmental trajectories of reading-related brain regions
- Sublexical vs. lexical processing during reading
- Pseudoword spelling as a window into sublexical representations
The Sublexical Toolkit
My primary engineering contribution is the Sublexical Toolkit, an upcoming open source language analysis package available in both R and Python. The toolkit provides researchers with comprehensive measures for analyzing spelling-sound relationships at multiple grain sizes.
Technical Contributions
My most impactful technical contributions to the toolkit involve building the computational linguistics infrastructure from the ground up:
-
NLP Data Pipeline: Built an end-to-end data ingestion and processing pipeline in Python that tokenizes words into phoneme-grapheme mapping units, resolves ambiguous segmentations, and produces structured representations suitable for downstream probability computation. This involved webscraping and parsing tens of thousands of words from several accredited dictionaries, handling edge cases in linguistic data, and ensuring data quality across multiple sources.
-
Phonographeme Probability Engine: Engineered the system that computes mapping and probability tables across syllabic positions and grain sizes – effectively a specialized language model for sublexical structure. The engine processes each word through syllabification (Maximum Onset Principle), segments it into phoneme-grapheme units, and accumulates positional frequency and probability statistics.
-
Dataset Expansion: Scaled the Toolkit’s dataset from 20,000 to 40,000+ words during the webscraping phase, ultimately curating a 22,474-word master list after deduplication and pronunciation conflict resolution.
-
Backend Refactoring: Refactored the Toolkit’s computational backend from R to Python, improving performance and maintainability while preserving the existing R interface for users who prefer it.
Multi-Level Word Decomposition
The toolkit parses each word at multiple linguistic grain sizes simultaneously. The diagram below illustrates how a single word flows through the pipeline – from raw letters to structured phoneme-grapheme, onset-rime, and onset-nucleus-coda representations.
This multi-level decomposition is the foundation of the toolkit’s 80+ derived measures. Each grain size captures different aspects of spelling-sound structure, and the probability engine computes positional statistics at every level.
Data Curation Pipeline
Building a research-quality dataset required significant data engineering. The pipeline below shows the journey from raw dictionary scrapes to the curated master word list.
Each stage involved custom tooling: the webscraper handled three different dictionary formats, the tokenizer resolved ambiguous phoneme-grapheme alignments, and the conflict resolution system flagged 1,380 pronunciation variants for manual review.
Reverse Mapping: Pseudoword Spelling
One of the toolkit’s most novel capabilities is pw_spell – a reverse phoneme-to-grapheme mapping function that generates plausible English spellings from phoneme sequences. This supports research on pseudoword spelling, where participants’ spelling choices reveal their internalized sublexical knowledge.
The function selects graphemes probabilistically based on the toolkit’s learned positional frequency tables, producing spellings that reflect real English orthographic patterns.
Dataset Characteristics
The toolkit’s 22,512-word vocabulary spans a wide range of word structures and frequency levels. The following visualizations were generated from the toolkit’s master sublexical unit spreadsheet.
Two-syllable words dominate the dataset (43.5%), with single-syllable and three-syllable words forming the next largest groups. Words with 6+ syllables are rare in English and account for less than 0.3% of the vocabulary.
Phoneme-grapheme unit counts follow a roughly normal distribution centered around 5-6 units per word. This reflects the average complexity of English spelling-sound correspondences in the toolkit’s vocabulary.
Word frequencies from the SUBTLEX-US corpus show the expected Zipfian pattern – most words in the dataset occur relatively infrequently in natural language, while a small number of high-frequency words (10K+) account for the bulk of everyday usage.
Toolkit Guide
I authored a comprehensive LaTeX reference document (the Toolkit Guide) that serves as the primary documentation for the toolkit’s measures, grain sizes, datasets, and functions. The guide covers the full taxonomy of 80+ derived measures, explains the syllabic position encoding scheme, and provides usage examples for both the R and Python interfaces.
Available Measures
The toolkit computes various sublexical measures including:
- Phonographeme (PG) probabilities across syllable positions
- Grapheme-phoneme (GP) mappings
- Frequency tables for syllable-initial, syllable-medial, and syllable-final positions
- Word-initial and word-final probability distributions
- Age-of-acquisition statistics
NTR Orthogonalization Library
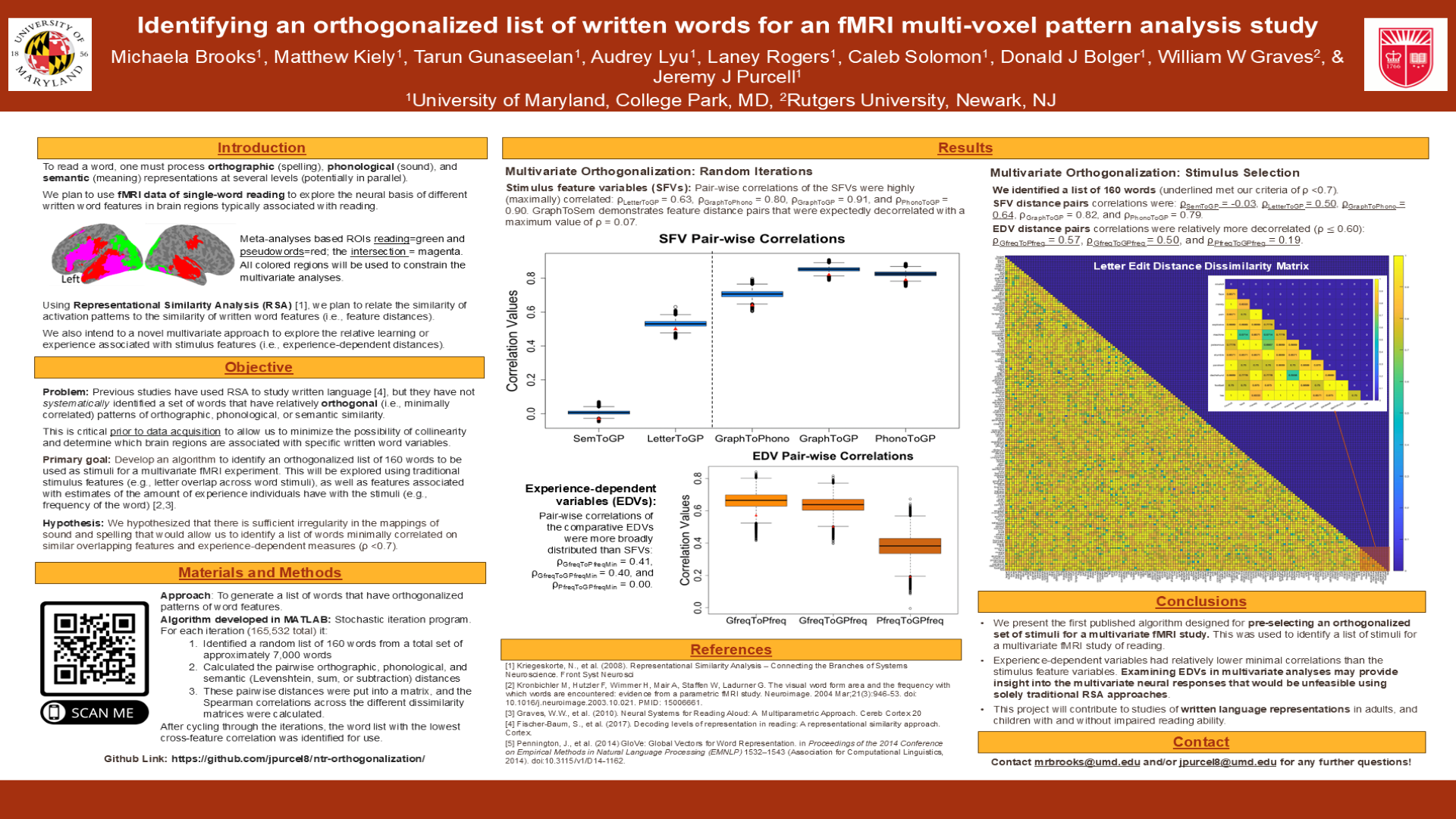
I developed the NTR Orthogonalization Library, a specialized MATLAB toolkit for constructing optimized word lists for fMRI block-based studies. The library ensures minimal correlation between words, helping researchers design more precise neuroimaging experiments.
Features
- Minimized Word Correlation: Constructs word lists with minimal inter-word correlations for cleaner fMRI signals
- Adjustable Parameters: Customize word list length while maintaining minimal correlation
- Visualization Tools: Generate distance matrices and correlation visualizations to aid study design
- Extensibility: Modular structure designed for easy adaptation to related projects
Algorithm
The core algorithm minimizes correlation between words by:
- Calculating pairwise correlations between words based on their semantic vectors (using GloVe embeddings)
- Creating a triangular distance matrix representing semantic distances
- Iteratively adjusting the word list to minimize overall correlation while maintaining desired length
The library draws on data from multiple sources including the English Lexicon Project (ELP) for word frequency data, IPHOD for biphone probabilities, and custom grapheme-phoneme mapping tables.
NTR Developmental Project
I contributed to the NTR Developmental Project, which generates linguistic measures across different age bins to analyze how reading develops over time. This work supports research into how sublexical processing changes as children learn to read.
Tools and Scripts
The project includes several analysis tools written in R:
- Age Bin Measures: Streamlined computation of measures across developmental age groups
- PG Probability Calculator: Computes phonographeme probabilities for lexical items
- GP Table Generator: Creates frequency and probability tables for grapheme-phoneme mappings at various syllable positions
Output tables cover syllable-initial, syllable-medial, syllable-final, word-initial, and word-final positions for frequency, PG, and GP measures.
Publications & Presentations
- Poster presented at the 2023 Society for Neuroscience (SfN) conference on the NTR Orthogonalization Library
- Poster presented at the 2025 Society for the Neurobiology of Language (SNL) conference on the Sublexical Toolkit (with Brooks as co-author)
- Technical analyses I’ve run support upcoming publications including work on pseudoword spelling and insights into sublexical representations and lexical interactions. These studies examine how measures of onset/rime consistency relate to lexical skill compared to phonographeme-level measures.
SfN 2023 — NTR Orthogonalization Library
SNL 2025 — Sublexical Toolkit & Pseudoword Spelling

Technologies
The lab’s computational work spans multiple languages and tools:
- Python: NLP pipelines, tokenization, webscraping, data validation, backend development
- R/RMarkdown: Statistical analysis, probability calculations, visualization
- MATLAB: Orthogonalization algorithms, matrix operations, fMRI study design tools
- LaTeX: Toolkit Guide documentation